Content for TR 22.876 Word version: 19.1.0
5.2 Local AI/ML model split on factory robots
5.2.1 Description
5.2.2 Pre-conditions
5.2.3 Service Flows
5.2.4 Post-conditions
5.2.5 Existing features partly or fully covering the use case functionality
5.2.6 Potential New Requirements needed to support the use case
...
...
5.2 Local AI/ML model split on factory robots p. 12
5.2.1 Description p. 12
In a modern factory, a team on a workstation comprises two human operators, two mobile robots and a fixed robot. Everyone has his own pre-defined task. Robots assist the human operators by accomplishing painful tasks in a fluid and precise manner; they also monitor that the workstation environment remains safe for the human operators. The mobile robots must not interfere with humans and between them.
The robot control is not executed on a distant server in the cloud because reliability and confidentiality were not ensured at a sufficient level. Furthermore, as stated in [14], the overall end-to-end latency is not always guaranteed which can cause production loss. Communications between robots can rely on private wireless networks in the factory that enable expected QoS (reliability, throughput, and latency) as well as confidentiality.
The new robots are autonomous robots that can react to human voices or learn in real-time what operators do. They can perceive their environment and transmit information to other robots. They can communicate, learn from each other, assist each other and do self-monitoring.
The autonomous robot's skills rely on several AI/ML models running on the robot itself which has the inconvenience that the mobile robot's battery drain quicker. To overcome this issue, when the battery level reaches a certain value, a part of the AI/ML model can be transferred to a service hosting environment and / or to another robot by splitting the AI/ML model as defined in [20]. The split model approach of [20] is applicable to a UE-to-UE (or robot-to-robot) architecture. Thus, the AI/ML model M is split and shared between (e.g.) 2 robots, say an assisted robot and an assistant robot. Intermediate data generated by the assisted robot are transferred to the assisting robot which finalizes the inference and transmits the results back to the assisted robot. This intermediate data transfer must be extremely efficient in terms of latency and throughput. When many models are at stake, the split model method is an additional challenge for the 5GS in terms of throughput, latency and synchronization.
Because they are more autonomous, mobile and smart, the industry 4.0 robots embed a large variety of sensors that generate huge amount of data to process. Table 5.2.1-1 reflects that variety.
Each type of sensing data requires a different AI/ML model. Each of these models produce predictions in a certain delay and with a certain accuracy.
Thus, as an offloading strategy, we can imagine that a model is split between 2 robots because it has been established that for a particular AI/ML model, the latency with the sidelink communication was better (smaller) than with the regular 5G communication path, as stated in [12] and [13].
At the same time, other AI/ML models are split between the robot and the service hosting environment because from an energy standpoint this configuration is the best.
Table 5.2.1-2 is an example of this offloading strategy where four AI/ML models are split between a robot and the service hosting environment and four other AI/ML models are split between two robots.
Sidelink and 5G communication paths are complementary from an AI/ML model split policy standpoint.
Table 5.2.1-1 shows some typical and diverse AI/ML models that can be used on robots. For each model, all the split point candidates have been considered and only the split points that generate the minimum and the maximum amount of intermediate data have been noted.
| Model Name | Model type | Intermediate data size (MB) | |||
|---|---|---|---|---|---|
| 8 bits data format | 32 bits data format | ||||
| Min | Max | Min | Max | ||
| AlexNet [21] | Image recognition | 0.02 | 0.06 | 0.08 | 0.27 |
| ResNet50 [22] | Image recognition | 0.002 | 1.6 | 0.008 | 6.4 |
| SoundNet [11] | Sound recognition | 0.0017 | 0.22 | 0.0068 | 0.88 |
| PointNet [15] | Point Cloud | 0.262 | 1.04 | 0.0068 | 4.19 |
| VGGFace [19] | Face recognition | 0.000016 | 0.8 | 0.000064 | 3.2 |
| Inception resnet | Face recognition | 0.0017 | 0.37 | 0.0068 | 1.51 |
In Table 5.2.1-2 the AI/ML models are distributed between the service hosting environment and the proximity robot. The way the models are distributed is out of scope of this use case and depends on various criteria as said previously. Therefore, the next Table is an example that illustrates the distribution. The intermediate data size is presented with the range [Min - Max], where Min and Max are respectively the sum of the Min values and the sum of the Max values of the selected models as defined in Table 5.2.1-1 (figures in bold).
| Model Name | Offloading target | Intermediate data size (MB) | Transfer time (ms) | Data rate (Gb/s) |
|---|---|---|---|---|
| AlexNet [21] | Proximity robot or Service Hosting Environment | [0.000016 - 1.6]
(8 bits data format) | 10 | [0.128 - 1.28] |
| ResNet50 [22] | ||||
| VGGFace [19] | ||||
| SoundNet [11] | [0.000064 - 6.4]
(32 bits data format) | 10 | [0.512 - 5.12] | |
| PointNet [15] | ||||
| Inception resnet |
As previously said latency is a critical requirement. Figure 5.2.1-3 summarizes the latency cost in three scenarios:
- The inference of model M is done locally. Latency is denoted LLI.
- The inference process is fully offloaded on a second device (Robot/UE). Latency is denoted LFO.
- The inference process is partially offloaded on a second device (Robot/UE). Latency is denoted LPO.
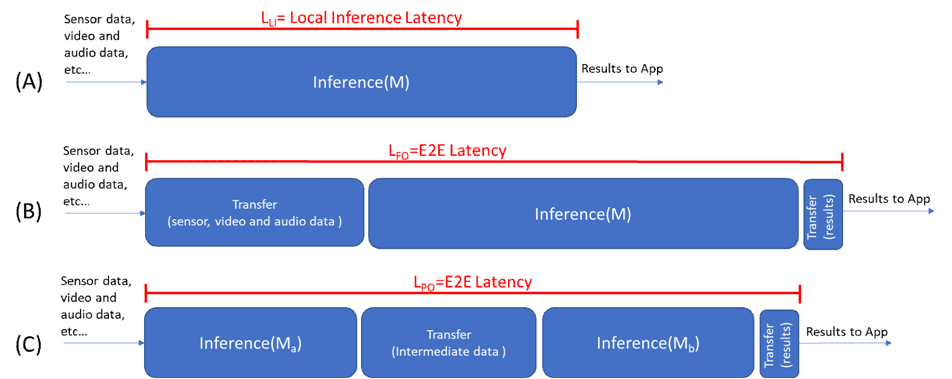
The current Use Case promotes the scenario (C) where a model M is split in two sub-models Ma and Mb. If both robots (UEs) have a similar computing power, the assumption is that the latency due to the inference of model M is almost equal to the latency of model Ma plus the latency of model Mb.
Hence, once the split model is deployed on the two robots (UEs), the aim is to minimize the E2E latency and to be as close as possible to the non-split case. This is done with a transfer delay of both the intermediate data and the inference results as small as possible. We can note that if the computing power on the assistant robot is more important, then scenario (C) would be the preferred scenario.
In scenario (B), the inference process is fully offloaded on the assistant robot (UE). The major inconvenience is the strong and negative impact on latency of the raw data transfer towards the assistant robot.
5.2.2 Pre-conditions p. 14
Two human operators are working.
Two mobile AI-driven robots (Arobot and Brobot) and one static AI-driven robot (Crobot) assist them.
The three robots (Arobot, Brobot and Crobot) belong to the same service area, embed the same two powerful AI/ML models M1 and M2, sensors (e.g. LIDAR, microphone) and cameras (e.g., 8K videos stream).
Arobot and Brobot are powered with a battery and Crobot with fixed ground power.
The three robots (Arobot, Brobot and Crobot) are connected, e.g., to the AF, 5GC, or to each other using D2D technologies (Prose, BT, WiFi, etc.).
The workstation is equipped with camera and sensors.
The service area is 30 m x 30 m and the robot speed is at maximum 10 km/h.
The service area is covered by a small cell and a service hosting environment is connected and can support AI/ML processes.
5.2.3 Service Flows p. 15
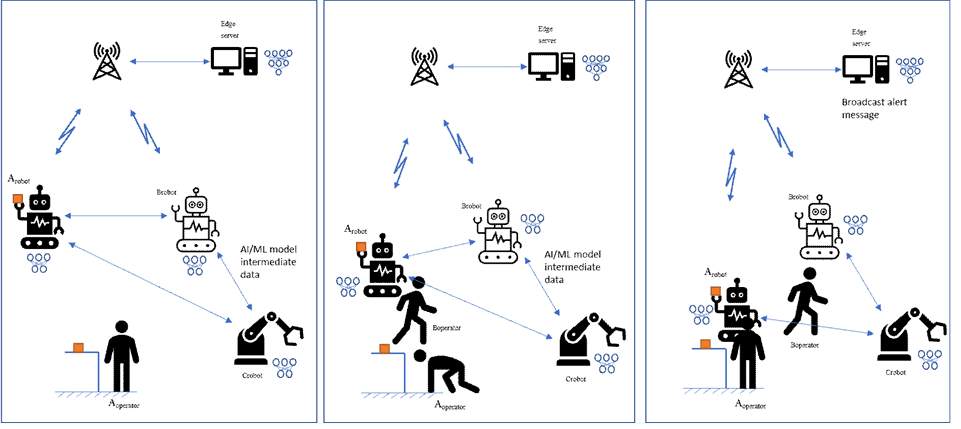
- Brobot battery level is rather low but it can still work for a while if a part of its machine learning process is offloaded.
- Brobot broadcasts a request message to get assistance. Crobot and the service hosting environment responds positively.
- Brobot negotiates with Crobot and the service hosting environment what parts of M1 and M2 respectively for the inference process they are in charge of, knowing that the quality of the prediction must not be under a certain level and that the end-to-end latency must not be above a certain value. M1 model is split between Brobot and the service hosting environment. M2 model is split between Brobot and Crobot.
- Brobot, Crobot and the service hosting environment agree on split points for both M1 and M2 models and Brobot starts sending the intermediate data to Crobot and the service hosting environment.
- Crobot infers and transmits using unicast mode with a very short delay the predictions back to Brobot. The service hosting environment infers and transmits using unicast mode the predictions back to Brobot in a very short delay.
- In the meanwhile, Arobot is carrying a load to the operator Aoperator.
- Aoperator bends down to pick up a screw that has fallen on the floor. At the same time Boperator is passing between Aoperator and Arobot. Arobot can't see Aoperator anymore.
- Brobot is busy with another task, but it can observe the scene. It reports the scene as intermediate data to Crobot and the service hosting environment.
- Crobot and the service hosting environment amend the ML model based on the new training data.
- Crobot and the service hosting environment infer and then transmit in unicast the prediction back to Brobot. The safety application on the service hosting environment collects the inference results.
5.2.4 Post-conditions p. 15
Intermediate data can be exchanged between two robots (UEs) and / or service hosting environment, and the robot with a low battery level can continue working for a while.
All the robots in the group receive the alert message and react:
- They all stop working; or
- Arobot changes its trajectory.
5.2.5 Existing features partly or fully covering the use case functionality p. 16
The Use Case can rely on the Proximity Service (ProSe) services as defined in TS 23.303.
Cyber-Physical Control Applications, see TS 22.104, already proposes to rely on a ProSe communication path. The proposed requirements are limited in terms of data transfer as shown in Table 5.2-1, where the message size does not exceed a few hundred of Bytes (250 kB at maximum).
Clause 6.40 of TS 22.261 provides requirements for AI/ML model transfer in 5GS. The requirements in this clause does not consider requirements for direct device connection.
In TS 22.261 Table 7.6.1-1, the max. end-to-end latency is 10 ms, the maximum data rate is [1] Gbits/s and reliability is 99.99% for Gaming or Interactive Data Exchanging.
| Use Cases | Characteristic parameter (KPI) | Influence quantity | ||||
|---|---|---|---|---|---|---|
| Max allowed end-to-end latency | Service bit rate: user-experienced data rate | Reliability | # of UEs | UE Speed | Service Area
(note 2) |
|
| Gaming or Interactive Data Exchanging
(note 3) | 10ms (note 4) | 0,1 to [1] Gbit/s supporting visual content (e.g. VR based or high definition video) with 4K, 8K resolution and up to120 frames per second content. | 99,99 % (note 4) | ≤ [10] | Stationary or Pedestrian | 20 m x 10 m; in one vehicle (up to 120 km/h) and in one train (up to 500 km/h) |
|
NOTE 1:
Unless otherwise specified, all communication via wireless link is between UEs and network node (UE to network node and/or network node to UE) rather than direct wireless links (UE to UE).
NOTE 2:
Length x width (x height).
NOTE 3:
Communication includes direct wireless links (UE to UE).
NOTE 4:
Latency and reliability KPIs can vary based on specific use case/architecture, e.g. for cloud/edge/split rendering, and can be represented by a range of values.
NOTE 5:
The decoding capability in the VR headset and the encoding/decoding complexity/time of the stream will set the required bit rate and latency over the direct wireless link between the tethered VR headset and its connected UE, bit rate from 100 Mbit/s to [10] Gbit/s and latency from 5 ms to 10 ms.
NOTE 6:
The performance requirement is valid for the direct wireless link between the tethered VR headset and its connected UE.
|
||||||
These requirements partially cover the current Use Case needs.
5.2.6 Potential New Requirements needed to support the use case p. 16
5.2.6.1 Potential Functionality Requirements p. 16
[P.R.5.2.6-001]
Subject to user consent and operator policy, the 5G system shall support the transfer of AI/ML model intermediate data from UE to UE via the direct device connection.
[P.R.5.2.6-002]
Subject to user consent and operator policy, the 5G system shall be able to provide means to predict and expose network condition changes (i.e. bitrate, latency, reliability) and receive user preferences on usage of the direct device connection or the direct network connection in order to meet the user experienced data rate and latency.
[P.R.5.2.6-003]
Subject to user consent and operator policy, the 5G system shall be able to dynamically select the intermediate device that is capable to perform the needed functionalities, e.g., AIML splitting.
[P.R.5.2.6-004]
Subject to user consent and operator policy, the 5G system shall be able to maintain the QoS (latency, reliability, data rate as defined in the Table 5.2.6.2-1 below) of the communication path of the direct device connection.
[P.R.5.2.6-005]
Subject to user consent and operator policy, the 5G system shall be able to have the means to modify the QoS of the communication path of the direct device connection.
5.2.6.2 Potential KPI Requirements p. 17
Based on Table 5.2.1-2, the potential KPI requirement is as below:
| Model Name | Payload size (Intermediate data size) | Max allowed end-to-end latency | Experienced data rate | Service area dimension | Communication service availability | Reliability |
|---|---|---|---|---|---|---|
| AlexNet [21] | 0.000016 - 1.6 MByte (8 bits data format) | 10 ms | 0.128 - 1.28 Gbps | 900 m2
(30 m x 30 m) | 99.999 % | 99.999 % |
| ResNet50 [22] | ||||||
| VGGFace [19] | ||||||
| SoundNet [11] | ||||||
| PointNet [15] | 0.000064 - 6.4 Mbyte (32 bits data format) | 10 ms | 0.512 - 5.12 Gbps | |||
| Inception resnet |
![]()
![]()
![]()