Content for TR 22.876 Word version: 19.1.0
7 Distributed/Federated Learning by leveraging direct device connection
7.1 Direct device connection assisted Federated Learning
7.1.1 Description
7.1.2 Pre-conditions
7.1.3 Service Flows
7.1.4 Post-conditions
7.1.5 Existing features partly or fully covering the use case functionality
7.1.6 Potential New Requirements needed to support the use case
7.1.6.1 Functional requirement
7.1.6.2 KPI requirement for direct device communication
...
...
7 Distributed/Federated Learning by leveraging direct device connection p. 24
7.1 Direct device connection assisted Federated Learning p. 24
7.1.1 Description p. 24
In many circumstances, an application server holding a Federated Learning (FL) task has a transmission delay requirement and limited FL coverage. An FL coverage means an area in which UEs the Application server can organize for federated learning.
An Application server has a transmission delay requirement for each FL member (UE). Some of UEs are actually holding valuable dataset but cannot fulfil transmission delay requirement, which leads to a decreasing of FL performance. However, if a UE's direct network connection cannot fulfil the transmission delay requirement (i.e. an QoS on Uu), leveraging the devices with direct connections helps to involve more UEs holding valuable dataset for the FL task with the following case study:
A UE-A with bad transmission condition sends a UE's training result to UE-B via direct device connection. In such case, a UE-B aggregates the training result locally and provides to UEs an update of training model for next round.
Some research e.g. in [6] [7] have illustrated the increasing performance in subcase-B (we call it "decentralized averaging methods"). In order to include more devices to participate in FL and to reduce the devices' reliance on the PS, the authors in [7] uses decentralized averaging methods to update the local ML model of each device. In particularly, using the decentralized averaging methods, each device only needs to transmit its local ML parameters to its neighboring devices. And the neighboring devices can use the acquired ML parameters to estimate the global ML model. Therefore, using the decentralized averaging methods can reduce the communication overhead of FL parameter transmission.

Figure 7.1-1: FL with decentralized averaging method outperforms the original FL
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
To show the performance of decentralized averaging method, the [6] implemented a preliminary simulation for a network that consists of one BS that is acted as an application server and six devices, as shown in Figure 7.1-1. In Figure 7.1-1, the green and purple lines respectively represent the local ML parameter transmission of original FL and the FL with decentralized averaging methods. Due to the transmission latency requirement, only 4 devices can participate in original FL. For the FL with the decentralized averaging update method, 6 devices can participate in the FL training process since the devices which are out of coverage can connect to their neighbouring devices (i.e. Device a and Device b) for model updating.
From Figure 7.1-1, we can see that the FL with decentralized averaging method outperforms the original FL in terms of identification accuracy. Specifically, the original FL (without using direct device connection) has an upper limit of identification accuracy to about 0.85, while using direct device connection for decentralized averaging method helps to increase the identification accuracy to about 0.88 which is actually a big optimization since the line already goes smoothly after 200 round of FL training.
Besides, the FL leveraging direct device connection can also reduce the energy consumption for some devices since it only needs to transmit its ML model parameters to device instead of the BS.
7.1.2 Pre-conditions p. 25
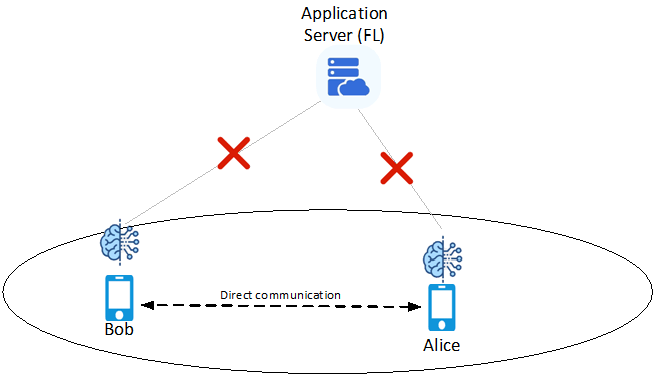
Figure 7.1-2: two UEs performs decentralized FL using Direct Device connection
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
As depicted in Figure-2, there is an Application server for federated learning which needs to communicate with the UEs in a FL coverage for FL task.
To achieve an ideal performance (i.e. fast convergence and high model accuracy), there is a transmission latency requirement to each FL member UE's data transmission.
Alice and Bob are FL members but their cell phones sometimes have bad signal condition which cannot transmit data to FL service directly. Meanwhile, Bob is willing to support the "decentralized averaging method" (as described in clause 7.1.1) service for its neighbouring cell phones.
Alice, Bob are neighbouring to each other within a FL coverage.
7.1.3 Service Flows p. 26
- Alice is a FL member and already acquires the global AI/ML model from the Application server for FL task, later on when Alice moves to a tunnel with bad signal condition, Alice cell phone's with direct device connection with her neighboring cell phone cannot transmit model data to its Application server anymore.
- In the tunnel, Alice discovers Bob, who is neighboring to Alice, a FL member and willing to activate the "decentralized averaging method" service. Thus, Alice requests Bob to establish a direct device connection so that Alice can transmit the AI/ML model training result to Bob.
- Bob updates the AI/ML model based on Alice's training result and Bob's local training result. And Bob sends the updated AI/ML model to Alice for further training.
7.1.4 Post-conditions p. 26
By leveraging direct device connection, Alice and Bob can keep the model training of a FL task even when they are under a bad network coverage. And the training result between Alice and Bob can be further uploaded to Application server for global model updating.
Thanks to leveraging direct device connection, it helps FL to be performed even when no communication availability to FL server. Such use case helps to optimize the FL performance.
7.1.5 Existing features partly or fully covering the use case functionality p. 26
In clause 6.40.2 of TS 22.261 v18.6.1
Based on operator policy, the 5G system shall be able to provide means to allow an authorized third-party to monitor the resource utilisation of the network service that is associated with the third-party.
Based on operator policy, the 5G system shall be able to provide an indication about a planned change of bitrate, latency, or reliability for a QoS flow to an authorized 3rd party so that the 3rd party AI/ML application is able to adjust the application layer behaviour if time allows. The indication shall provide the anticipated time and location of the change, as well as the target QoS parameters.
Based on operator policy, 5G system shall be able to provide means to predict and expose predicted network condition changes (i.e. bitrate, latency, reliability) per UE, to an authorized third party.
Subject to user consent, operator policy and regulatory constraints, the 5G system shall be able to support a mechanism to expose monitoring and status information of an AI-ML session to a 3rd party AI/ML application.
Subject to user consent, operator policy and regulatory requirements, the 5G system shall be able to expose information (e.g. candidate UEs) to an authorized 3rd party to assist the 3rd party to determine member(s) of a group of UEs (e.g. UEs of a FL group).
7.1.6 Potential New Requirements needed to support the use case p. 27
7.1.6.1 Functional requirement p. 27
[P.R.7.1-001]
Based on user consent and operator policies, the 5G system shall be able to configure a group of UEs who participate in the same service group (e.g. for the same AI-ML FL task) to establish communication with each other via direct device connection e.g. when direct network connection cannot fulfil the required QoS.
[P.R.7.1-002]
Based on user consent, operator policies and the request from an authorized 3rd party, the 5G system shall be able to dynamically add or remove UEs to/from the same service (e.g. a AI-ML federated learning task) when communicating via direct device connection.
7.1.6.2 KPI requirement for direct device communication p. 27
The 5G system shall be able to support the following KPI for direct device connection as defined in Table 7.1.6-1.
| Model size
(8 bit VGG-16 BN) (see NOTE 2) |
Mini-batch size
(images) |
Maximum latency for trained gradient uploading and global model distribution (see NOTE 1) | User experienced UL/DL data rate for trained gradient uploading and global model distribution (see NOTE 2) |
|---|---|---|---|
| 132 Mbyte | 64 | 3.24s | 325Mbit/s |
| 32 | 1.9s | 55Mbit/s | |
| 16 | 1.3s | 810Mbit/s | |
| 8 | 1.1s | 960Mbit/s | |
| 4 | 1.04s | 1.0Gbit/s | |
|
NOTE 1:
Latency in this Table is assumed 20 times the device GPU computation time for the given mini-batch size.
NOTE 2:
Values provided in the table are calculative needs for an 8-bit VGG16 BN model with 132MByte size [2].
|
|||
![]()
![]()
![]()