Content for TR 26.865 Word version: 18.0.0
4.2 Audio Architectures for Split Rendering Scenarios
4.2.1 Introduction
4.2.2 Local Audio Rendering
4.2.3 Distributed Audio Rendering
4.2.4 Remote Audio Rendering
...
...
4.2 Audio Architectures for Split Rendering Scenarios p. 16
4.2.1 Introduction p. 16
An XR scene usually comprises both visual and audio media. Within the scope of ISAR the visual media follows a split rendering approach, where decoding and (pre-)rendering are performed by a capable device (e.g., an edge server), and limited processing with lower complexity is performed on the lightweight UE.
For the immersive audio media, different constraints in terms of complexity and memory as well as constraints related to relevant interfaces between remote presentation engine and End Device such as bit rate, latency (including motion-to-sound latency), down- and upstream link characteristics may apply.
The following generic architectures illustrate the separation of decoding and rendering of the downstream audio between lightweight UE and capable devices, limited to the data flow relevant to the application of the pose information for head-tracked binaural audio.
Selection of an architecture has an impact on complexity and memory as well as applicability to relevant interfaces between remote presentation engine and End Device due to bit rate, latency (including motion-to-sound latency), down- and upstream traffic characteristics.
4.2.2 Local Audio Rendering p. 17
The immersive audio data is streamed directly to the lightweight UE, which is responsible for decoding, rendering, and synchronizing the audio with the corresponding visual content. The lightweight UE processes the pose information locally and adjusts the audio rendering accordingly to create a convincing immersive experience.
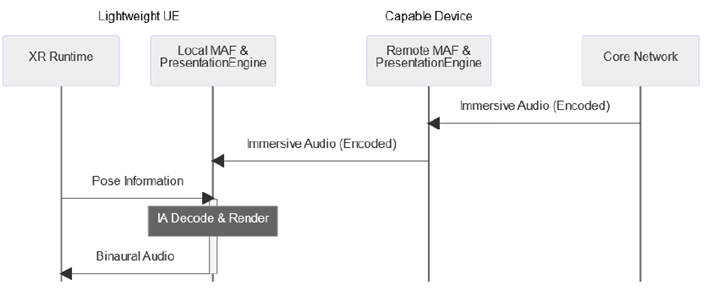
Figure 4.2-1: Sequence of data flow for Architecture 1, Local Audio Rendering
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
4.2.3 Distributed Audio Rendering p. 17
The capable device performs decoding and pre-rendering of the immersive audio media, and the pre-rendered audio is transmitted to the lightweight UE. The pose information is sent to the capable device if needed, which adjusts the pre-rendering based on the pose data to generate an 'intermediate representation'. The lightweight UE then performs decoding of the received intermediate representation and applies post-rendering for pose correction using a recent pose information
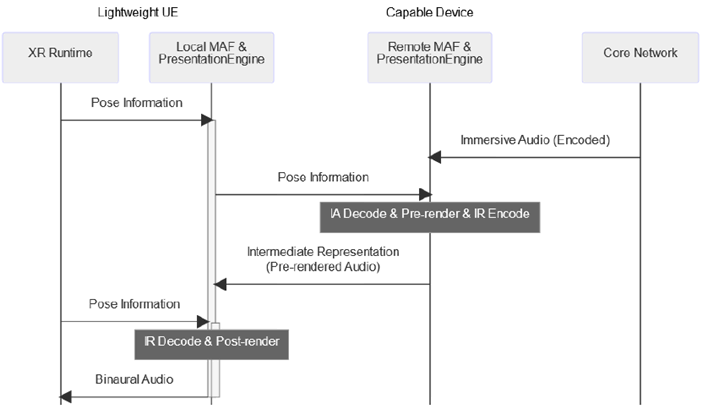
Figure 4.2-2: Sequence of data flow for Architecture 2, Distributed Audio Rendering
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
4.2.4 Remote Audio Rendering p. 18
The capable device is responsible for decoding and fully rendering the immersive audio media and encoding the rendered audio into an 'intermediate representation', containing coded binaural audio. The intermediate representation is transmitted to the lightweight UE, which performs decoding of the rendered media. The lightweight UE synchronizes the binaural audio with the corresponding visual content.
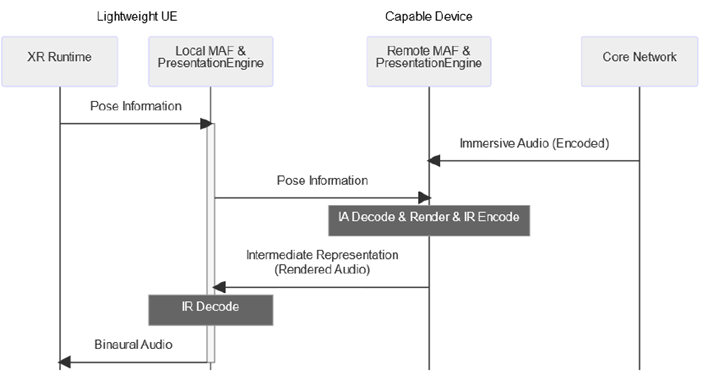
Figure 4.2-3: Sequence of data flow for Architecture 3, Remote Audio Rendering
(⇒ copy of original 3GPP image)
(⇒ copy of original 3GPP image)
![]()
![]()
![]()