Content for TS 26.249 Word version: 18.0.0
0 Introduction
1 Scope
2 References
3 Definitions of terms, symbols and abbreviations
3.1 Terms
3.2 Symbols
3.3 Abbreviations
4 General description of split renderer
4.1 Introduction
4.2 ISAR system overview
...
...
0 Introduction p. 5
An essential architectural characteristic of XR clients is the reliance on a functional split between a set of composite pre-renderers that are implemented as parts of a presentation engine and a set of post-rendering operations implemented on an End Device prior to final output. Split rendering may be a necessity if the End Device is power constrained or limited in computational power. However, split rendering is not precluded from other End Devices that do not have such constraints. A discussion of relevant split rendering scenarios is provided in TR 26.865, together with general design guidelines for immersive audio split rendering systems and specific design constraints and performance requirements for split rendering solutions for the 3GPP IVAS codec [1]. The latter are the basis for the split rendering feature of the IVAS codec. This TS presents ISAR split rendering solutions in a detailed algorithmic description, applicable even for other coding systems and renderers, whereby the split rendering solutions of the IVAS codec constitute a baseline set of the provided split rendering solutions.
1 Scope p. 6
The present document is a detailed algorithmic description of Split Rendering functions (ISAR) addressing Immersive Audio for Split Rendering Scenarios and that are applicable to a broad range of immersive audio coding systems and renderers. Functional solutions are described on an algorithmic level. Annexes of this document specify APIs, RTP payload format and SDP parameters as well as source code and test vectors.
2 References p. 6
The following documents contain provisions which, through reference in this text, constitute provisions of the present document.
- References are either specific (identified by date of publication, edition number, version number, etc.) or non-specific.
- For a specific reference, subsequent revisions do not apply.
- For a non-specific reference, the latest version applies. In the case of a reference to a 3GPP document (including a GSM document), a non-specific reference implicitly refers to the latest version of that document in the same Release as the present document.
[1]
TR 21.905: "Vocabulary for 3GPP Specifications".
[2]
TR 26.865: "Immersive Audio for Split Rendering Scenarios; Requirements ".
[3]
TS 26.250: "Codec for Immersive Voice and Audio Services (IVAS); General overview".
[4]
TS 26.253: "Codec for Immersive Voice and Audio Services (IVAS); Detailed Algorithmic Description incl. RTP payload format and SDP parameter definitions".
[5]
TS 26.258: "Codec for Immersive Voice and Audio Services (IVAS); C code (floating-point)".
[6]
TS 26.252: "Codec for Immersive Voice and Audio Services (IVAS); Test sequences".
3 Definitions of terms, symbols and abbreviations p. 6
3.1 Terms p. 6
Void
3.2 Symbols p. 6
Void
3.3 Abbreviations p. 6
For the purposes of the present document, the abbreviations given in TR 21.905 and the following apply. An abbreviation defined in the present document takes precedence over the definition of the same abbreviation, if any, in TR 21.905.
CLDFB
Complex Low-delay Filter Bank
DoF/DOF
Degree of Freedom
ISAR
Immersive Audio for Split Rendering
IVAS
Immersive Voice and Audio Services
LCLD
Low Complexity Low Delay
LC3plus
Low Complexity Communication Codec Plus
MD
Medadata
4 General description of split renderer p. 7
4.1 Introduction p. 7
The main part of the present document is a detailed algorithmic description of functions for Split Rendering of immersive audio. It comprises
- Intermediate pre-rendered audio representation,
- Encoder, bitstream and decoder for the intermediate representation,
- Post-rendering of the decoded intermediate representation to provide binaural audio output with and without head-tracker input and post-rendering control metadata.
4.2 ISAR system overview p. 7
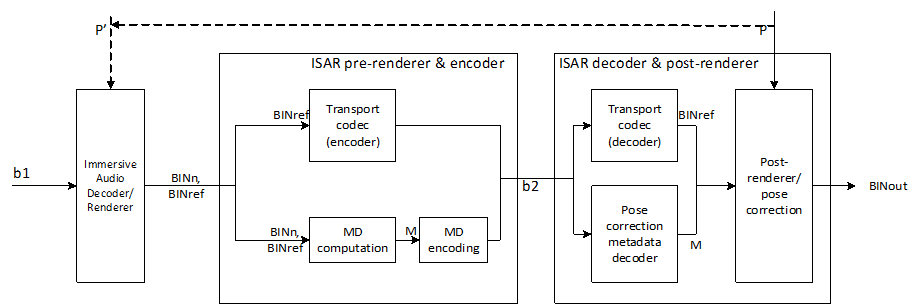
This clause provides a generic ISAR systems overview based on the example of the ISAR compliant IVAS split rendering feature, which define the baseline ISAR system illustrated in Figure 4.2-1.
The immersive audio rendering process is split between a capable device or network node (by the Presentation Engine relying on IVAS decoding and rendering) and a less capable device with limited computing and memory resources and motion-sensing for head-tracked binaural output. ISAR split rendering consists of the following core components:
-
Pre-renderer & encoder with
- Pose correction metadata computation and metadata encoder
- Binaural audio encoder (transport codec encoder)
-
ISAR decoder & post-renderer with
- Pose correction metadata decoder
- Binaural audio decoder (transport codec decoder)
- Pose corrective post renderer
![]()
![]()
![]()