TS 26.250
Codec for Immersive Voice and Audio Services (IVAS)
General overview
V18.2.0 (PDF)
2024/12 … p.
- Rapporteur:
- Dr. Bruhn, Stefan
Dolby Sweden AB
Content for TS 26.250 Word version: 18.0.0
1 Scope
2 References
3 Definitions of terms, symbols and abbreviations
4 General
5 Transcoding functions
6 Rendering
7 C-code
8 Test sequences
9 Discontinuous transmission (DTX)
10 Error concealment of lost frames
11 Frame structure
12 RTP Payload Format
13 Jitter Buffer Management
14 Performance characterization
A Change history
1 Scope p. 6
The present document is an introduction to the audio processing parts and auxiliary functions of the codec for Immersive Voice and Audio Services (IVAS codec). A general overview of the audio processing and auxiliary functions is given, with reference to the documents where each function is specified in detail.
2 References p. 6
The following documents contain provisions which, through reference in this text, constitute provisions of the present document.
- References are either specific (identified by date of publication, edition number, version number, etc.) or non-specific.
- For a specific reference, subsequent revisions do not apply.
- For a non-specific reference, the latest version applies. In the case of a reference to a 3GPP document (including a GSM document), a non-specific reference implicitly refers to the latest version of that document in the same Release as the present document.
[1]
TR 21.905: "Vocabulary for 3GPP Specifications".
[2]
TS 26.441: "Codec for Enhanced Voice Services (EVS); General Overview".
[3]
TS 26.253: "Codec for Immersive Voice and Audio Services (IVAS); Detailed Algorithmic Description incl. RTP payload format and SDP parameter definitions".
[4]
TS 26.254: "Codec for Immersive Voice and Audio Services (IVAS); Rendering".
[5]
TS 26.251: "Codec for Immersive Voice and Audio Services (IVAS); C code (fixed-point)".
→ to date, still a draft
[6]
→ to date, still a draft
TS 26.258: "Codec for Immersive Voice and Audio Services (IVAS); C code (floating point)".
[7]
TS 26.252: "Codec for Immersive Voice and Audio Services (IVAS); Test Sequences".
[8]
TS 26.255: "Codec for Immersive Voice and Audio Services (IVAS); Error concealment of lost packets".
[9]
TS 26.256: "Codec for Immersive Voice and Audio Services (IVAS); Jitter Buffer Management".
[10]
TR 26.997: "Codec for Immersive Voice and Audio Services (IVAS); Performance characterization".
[11]
TS 26.131: "Terminal acoustic characteristics for telephony; Requirements".
[12]
TS 26.261: "Terminal audio quality performance requirements for immersive audio services".
[13]
TS 26.114: "IP Multimedia Subsystem (IMS); Multimedia telephony; Media handling and interaction".]
3 Definitions of terms, symbols and abbreviations p. 6
3.1 Terms p. 6
For the purposes of the present document, the terms given in TR 21.905 and the following apply. A term defined in the present document takes precedence over the definition of the same term, if any, in TR 21.905.
3.2 Symbols p. 7
Void.
3.3 Abbreviations p. 7
For the purposes of the present document, the abbreviations given in TR 21.905 and the following apply. An abbreviation defined in the present document takes precedence over the definition of the same abbreviation, if any, in TR 21.905.
EVS
Enhanced Voice Services
IVAS
Immersive Voice and Audio Services
JBM
Jitter Buffer Management
MASA
Metadata-Assisted Spatial Audio
SID
Silence Insertion Descriptor
4 General p. 7
The codec for Immersive Voice and Audio Services is part of a framework comprising besides encoder and decoder, renderer and a number of auxiliary functions associated with the support of stereo and immersive audio formats.
The IVAS codec is an extension of the 3GPP Enhanced Voice Services (EVS) codec; it provides full and bit exact EVS codec functionality for mono speech/audio signal input.
On top of that the IVAS codec is optimized for encoding and decoding of stereo and immersive audio formats, using tools such as Single Channel Element (SCE) coding, Channel Pair Element (CPE) coding and multi-channel coding by means of the Multi-channel Coding Tool (MCT). The stereo modes comprise a hybrid time-domain/DFT-domain/MDCT-domain coding scheme including inter channel alignment (ICA). Immersive audio formats comprise multi-channel audio (5.1, 5.1.2, 5.1.4, 7.1, 7.1.4 setups), scene-based audio (Ambisonics up to order 3), metadata-assisted spatial audio (MASA), and object-based audio (Independent Stream with Metadata (ISM) up to 4 ISMs). In addition, the following combined immersive audio formats are supported: object-based audio with scene-based audio (OSBA, up to 4 ISMs with Ambisonics) and object-based audio with metadata-assisted spatial audio (OMASA, up to 4 ISMs with MASA).
The codec features VAD/DTX/CNG for rate efficient stereo and immersive conversational voice transmissions, an error concealment mechanism to combat the effects of transmission errors and lost packets. Jitter buffer management is also provided.
The IVAS codec operates on 20 ms audio frames. It is capable of switching its bit rate upon command instantly at (active) frame boundaries.
A reference configuration where relevant interface signals and various relevant send side processing functions are identified is given in Figure 1. A corresponding reference configuration for receive side identifying relevant interface signals and processing functions is given in Figure 2. In the figures, the relevant specifications for each function are also indicated.
In Figure 1 and Figure 2, the UE Send and Receive Audio processing are included, to show the complete path between the audio input/output in the User Equipment (UE) and a possible digital interface in network (all excluding A/D or D/A conversion). The detailed specification of the audio parts is not within the scope of the present document. These aspects are only considered to the extent to highlight that the function of the audio parts and the operation of the IVAS codec are closely dependent on each other.
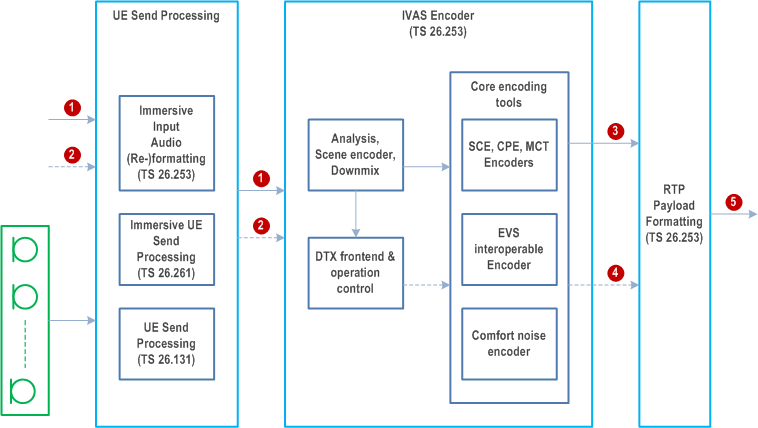
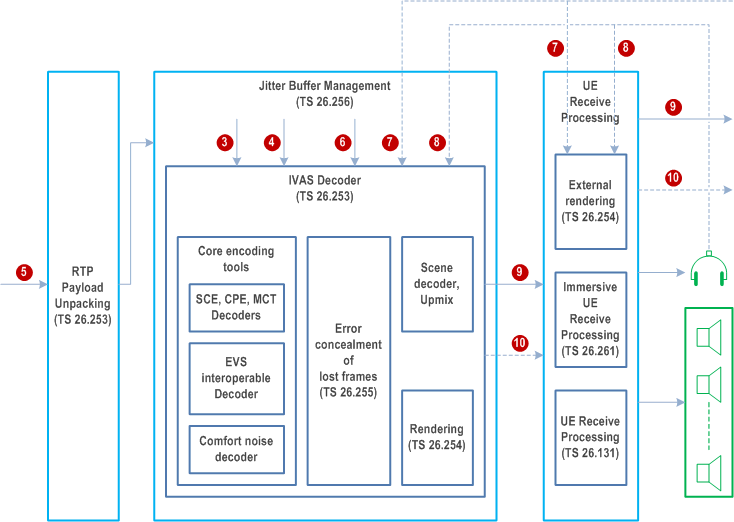
Interfaces:
1:
Audio input channels (16-bit linear PCM, sampled at 8 (only EVS), 16, 32, or 48 kHz)
2:
Metadata associated with input audio
3:
Encoded audio frames (50 frames/s), number of bits depending on IVAS codec mode
4:
Encoded Silence Insertion Descriptor (SID) frames
5:
RTP Payload packets
6:
Lost Frame Indicator (BFI)
7:
Renderer config data
8:
Head-tracker pose information and scene orientation control data
9:
Audio output channels (16-bit linear PCM, sampled at 8 (only EVS), 16, 32, or 48 kHz)
10:
Metadata associated with output audio
5 Transcoding functions p. 9
An algorithmic description of the IVAS codec is provided in TS 26.253.
As shown in Figure 1 and Figure 2, the audio encoder takes its input, and can produce an output at the decoder/renderer, in various audio output formats. Input and output audio signals consist of one or multiple constituent channels of the respective audio format and in some cases metadata. The constituent channels are in the form of 16-bit uniform Pulse Code Modulated (PCM) signals at sampling frequencies of 8 kHz (only EVS interoperable coding), 16 kHz, 32 kHz or 48 kHz. The audio may typically originate from and terminate within the audio part of the UE or from the network side.
The detailed mapping between blocks of input audio to encoded blocks (in which the number of bits depends on the presently used codec mode) and from these to output blocks of reconstructed audio is described in TS 26.253. The supported bit rates of the EVS interoperable coding are provided in TS 26.441. Stereo and immersive audio coding is offered at the following discrete bit rates [kbps]: 13.2, 16.4, 24.4, 32, 48, 64, 80, 128, 160, 192, 256, 384, and 512, with supported bit rate ranges and supported source-controlled rate operation (DTX) listed in Table 1.
| Input audio format | Range of supported bit rates (kbps) | Source Controlled Rate Operation Available |
|---|---|---|
| Stereo, binaural audio (note 1) | 13.2 - 256 | Yes, up to 256 kbps |
| Scene-based audio (Ambisonics: FOA, HOA2, HOA3) | 13.2 - 512 | Yes, up to 80 kbps |
| Metadata-assisted spatial audio (MASA) | 13.2 - 512 | Yes, up to 512 kbps |
| Object-based audio (ISM) (note 2) | 13.2 - 512 (note 3) | Yes, up to 512 kbps |
| Multi-channel audio | 13.2 - 512 | No |
|
NOTE 1:
A head-trackable binaural audio format at rates ranging from 256 kbps to 768 kbps is additionally supported as intermediate split rendering representation.
NOTE 2:
Combined input audio format combining scene-based audio with ISM (OSBA) is supported. Metadata-assisted spatial audio with ISM (OMASA) is supported.
NOTE 3:
13.2 kbps - 128 kbps for 1 ISM, 16.4 kbps - 256 kbps for 2 ISMs, 24.4 kbps - 384 kbps for 3 ISMs, resp. 24.4 kbps - 512 kbps for 4 ISMs.
|
||
For stereo input, a downmix tool is provided to generate a mono signal for EVS interoperable stream without additional delay.
6 Rendering p. 9
IVAS rendering is the process to generate the IVAS audio output in the same or a different audio format than the input format, whereby in some cases, such as stereo-to-stereo, there is no particular rendering processing other than the decoding. The IVAS decoder provides integrated binaural rendering functionality for headphone reproduction including head-tracking and scene orientation control and integrated rendering for loudspeaker reproduction. IVAS binaural rendering also supports a reverberation effect. There is also the possibility to feed the IVAS decoder output to a customized external renderer while bypassing the integrated renderer. A special feature of the renderer is that it supports split operation with pre-rendering and transcoding to a head-trackable intermediate representation that can be transmitted to a post-rendering end-device. This enables moving a large part of the processing load and memory requirements for IVAS decoding and rendering to a (more) capable node/UE while offloading the final rendering end-device.
IVAS rendering can also be operated stand-alone, i.e., without prior IVAS encoding/decoding of the input audio signal.
IVAS rendering is described in TS 26.253 and TS 26.254.
7 C-code p. 10
The C-code of the IVAS codec including VAD/DTX/CNG functionality, rendering, error concealment of lost frames, Jitter Buffer Manager (JBM) are described in TS 26.251 [5] for fixed point arithmetic operation and are described in TS 26.258 for floating point arithmetic operation.
The C-code is mandatory.
8 Test sequences p. 10
A set of digital test sequences is specified in TS 26.252, thus enabling the verification of compliance, i.e., bit-exactness, to a high degree of confidence.
The IVAS encoder, decoder and renderer (see Figure 1 and Figure 2) are defined in bit-exact arithmetic. Consequently, they shall react on being presented with a given input sequence always with the corresponding bit-exact output sequence, provided that the internal state variables are also always exactly in the same state at the beginning of the test.
The input test sequences shall produce the corresponding output test sequences, provided that the codec is operated from reset state.
9 Discontinuous transmission (DTX) p. 10
The discontinuous transmission (DTX) functionality of the IVAS codec including voice activity detection (VAD) and comfort noise generation (CNG) is defined in TS 26.253. DTX functionality is supported for IVAS operation modes, i.e., audio formats and bit rates, that are especially optimized for efficient stereo and immersive conversational voice transmissions (see Table 1).
During a normal telephone conversation, the participants alternate so that, on the average, each direction of transmission is occupied about 50% of the time. Source-controlled rate operation is a mode of operation where the encoder encodes speech frames containing only background noise with a lower bit rate than normally used for encoding speech. A network may adapt its transmission scheme to take advantage of the varying bit rate. This may be done for the following two purposes:
- In the UE, battery life will be prolonged, or a smaller battery could be used for a given operational duration.
- The average required bit rate is reduced, leading to a more efficient transmission with decreased load and hence increased capacity.
- a Voice Activity Detector (VAD) or more accurately Sound Activity Detector (SAD) on the TX side;
- evaluation of the background acoustic noise on the TX side, in order to transmit characteristic parameters to the RX side;
- generation of comfort noise on the RX side during periods when no normal speech frames are received.
10 Error concealment of lost frames p. 10
The IVAS codec error concealment of erroneous or lost frames is described in TS 26.253 and TS 26.255.
Frames may be erroneous due to transmission errors or frames may be lost or delayed due to packet loss in a transport network.
In order to mask the effect of erroneous/lost frames, the decoder shall be informed about such frames, which shall initiate error concealment actions leading to generation of substitution frames for the decoded/rendered audio output.
11 Frame structure p. 11
The IVAS codec frame structure is described in TS 26.253.
12 RTP Payload Format p. 11
The IVAS coder RTP Payload Format for media handling and interaction is described in TS 26.253.
13 Jitter Buffer Management p. 11
The IVAS codec Jitter Buffer Management is described in TS 26.256.
14 Performance characterization p. 11
The IVAS codec performance characterization is described in TR 26.997.
A Change history p. 12
![]()
![]()