TS 26.255
Codec for Immersive Voice and Audio Services (IVAS)
Error concealment of lost packets
V18.2.0 (PDF)
2024/09 12 p.
- Rapporteur:
- Mr. Norvell, Erik
Ericsson LM
Content for TS 26.255 Word version: 18.1.0
1 Scope
2 References
3 Definitions of terms, symbols and abbreviations
4 General
5 Error concealment in the core decoder
6 Error concealment per audio format
7 SID frame concealment operation
8 Error concealment for IVAS split rendering
$ Change history
1 Scope p. 6
The present document defines a frame loss concealment procedure, also termed frame substitution and muting procedure, which is executed by the Immersive Voice and Audio Services (IVAS) decoder when one or more frames (speech or audio or SID frames) are unavailable for decoding due to e.g. packet loss, corruption of a packet or late arrival of a packet.
2 References p. 6
The following documents contain provisions which, through reference in this text, constitute provisions of the present document.
- References are either specific (identified by date of publication, edition number, version number, etc.) or non-specific.
- For a specific reference, subsequent revisions do not apply.
- For a non-specific reference, the latest version applies. In the case of a reference to a 3GPP document (including a GSM document), a non-specific reference implicitly refers to the latest version of that document in the same Release as the present document.
[1]
TR 21.905: "Vocabulary for 3GPP Specifications".
[2]
TS 26.445: "Codec for Enhanced Voice Services (EVS); Detailed Algorithmic Description".
[3]
TS 26.447: "Codec for Enhanced Voice Services (EVS); Error Concealment of Lost Packets".
[4]
TS 26.253: "Codec for Immersive Voice and Audio Services - Detailed Algorithmic Description incl. RTP payload format and SDP parameter definitions".
[5]
TS 26.249: "Immersive Audio for Split Rendering Scenarios; Detailed Algorithmic Description of Split Rendering Functions".
3 Definitions of terms, symbols and abbreviations p. 6
3.1 Terms p. 6
For the purposes of the present document, the terms given in TR 21.905 and the following apply. A term defined in the present document takes precedence over the definition of the same term, if any, in TR 21.905.
Further IVAS codec specific definitions are found in clause 3.1 of TS 26.253.
3.2 Symbols p. 6
Void
3.3 Abbreviations p. 6
For the purposes of the present document, the abbreviations given in TR 21.905 and the following apply. An abbreviation defined in the present document takes precedence over the definition of the same abbreviation, if any, in TR 21.905.
BFI
Bad Frame Indicator
CPE
Channel Pair Element
DFT
Discrete Fourier Transform
ECU
Error Concealment Unit
EVS
Enhanced Voice Services
HQ MDCT
High Quality MDCT mode
IVAS
Immersive Voice and Audio Services
MASA
Metadata-Assisted Spatial Audio
MC
Multi-channel Audio
MCT
Multi-channel Coding Tool
MDCT
Modified Discrete Cosine Transform
OMASA
Objects and Metadata-Assisted Spatial Audio
OSBA
Objects and Scene-Based Audio
PLC
Packet Loss Concealment
SBA
Scene-Based Audio
SCE
Single Channel Element
4 General p. 7
Packet loss concealment serves to ensure the availability of useful audio output when valid packets are unavailable to the decoder. These losses are typically a result of impaired channel conditions like transmission errors or network congestion. The aim is to synthesize a substitution of the decoded audio represented by the lost packet, to prepare for a potential future packet loss, and to handle the transition from the concealment operation back to the decoded audio. The latter is also referred to as recovery operation. An overview of the IVAS codec's decoder operation is given in clause 6.1 of TS 26.253, where Figure 6.1-1 shows the functional structure of the decoder. To complement the picture with the packet loss concealment functionality, Figure 1 below shows the packet loss concealment (PLC) operation of the decoder. A major part of the PLC resides in the core decoding tools, where the audio decoding is mainly handled by the core decoder based on EVS [2]. The Single Channel Elements (SCE) decoder comprises one core-decoder, the Channel Pair Elements (CPE) comprises one or two core-decoders and the Multichannel Coding Tool (MCT) comprises joint decoding using multiple core-decoders, all including associated PLC methods. For the Low Frequency Effect (LFE) channel of multichannel audio, an LFE decoder with associated PLC method is available. Spatial metadata including spatial coding parameters are reconstructed in the spatial parameter decoders or by the associated PLC methods of the respective spatial audio formats. Spatial audio output is finally generated by a scene decoder, upmixer and renderer based on the reconstructed transport channels and the reconstructed spatial metadata. In case of a missing or corrupted packet, a bad frame indicator (BFI) is input to the decoding tools, activating the PLC operation. Notably, scene decoding, upmixing and rendering processing are independent of a bad frame indicator.
The IVAS split rendering feature exposes a further interface, the interface between the entity carrying out pre-rendering and encoding into the intermediate audio representation and the end-device doing post-rendering. To cope with potential transmission errors on that interface, the decoder of the intermediate audio representation features packet loss concealment techniques besides the actual decoding scheme. Note that the IVAS specific split rendering functionality including packet-loss concealment is mostly described in TS 26.253 whereas more generic split rendering functionality is specified in TS 26.249.
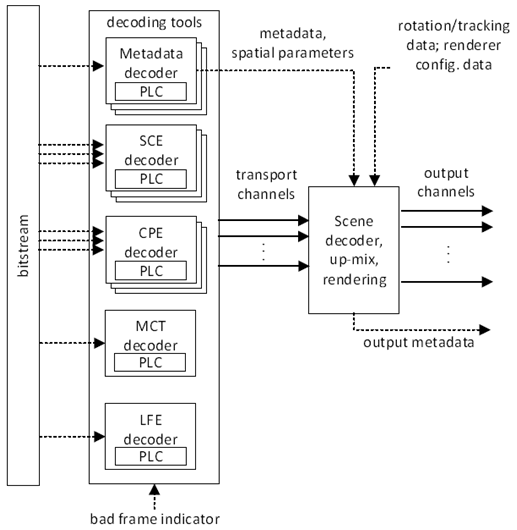
5 Error concealment in the core decoder p. 8
Since IVAS is based on the Codec for Enhanced Voice Services (EVS) [2], the main functionality of the core-codec is inherited from EVS. This includes the error concealment operations as described in TS 26.447, and for mono operation the functionality is implemented in a bit-exact manner. IVAS provides a few enhancements of the core-coder on top of EVS.
The following clauses in TS 26.253 describe the enhancements that have been made for the error concealment operation for the IVAS core-coder:
- PLC Method selection in HQ MDCT error concealment can be found in clause 6.2.2.3.4 of TS 26.253.
- Phase ECU enhancements can be found in clause 6.2.2.3.5 of TS 26.253.
6 Error concealment per audio format p. 8
In addition to the mono operation with EVS compatibility, IVAS supports stereo, Independent Streams with metadata (ISM), multi-channel audio (MC), scene-based audio (Ambisonics or SBA), metadata assisted spatial audio (MASA) and combinations of objects with MASA (OMASA) and combination of objects with scene-based audio (OSBA). To handle the variation in audio formats across the supported range of input audio channels and bit rates, several dedicated encoding and decoding modules are employed. The general principle is that the parameters are recycled from the previously decoded frame, but there may also be further concealment operators performed on the parameters. The following clauses in TS 26.253 describe the error concealment operations within each of modules decoding the various audio formats.
- MCT PLC can be found in clause 6.2.3.4.10 of TS 26.253.
- DFT-based stereo parameter error concealment can be found in clause 6.3.2.3.10 of TS 26.253.
- PLC in MDCT-based stereo can be found in clause 6.3.3.7 of TS 26.253.
- PLC in the SBA format decoder can be found in clause 6.4.8 of TS 26.253.
- PLC in the MASA format decoder can be found in clause 6.5.5 of TS 26.253.
- PLC in the ISM format decoder can be found in clause 6.6.5 of TS 26.253.
- LFE channel PLC within the MC format decoder can be found in clause 6.7.1.7 of TS 26.253.
- McMASA mode PLC within the MC format decoder can be found in clause 6.7.2.5 of TS 26.253.
- ParamMC mode PLC within the MC format decoder can be found in clause 6.7.3.7 of TS 26.253.
- Discrete MC mode PLC within the MC format decoder can be found in clause 6.7.5.2 of TS 26.253.
- PLC in the OSBA format decoder can be found in clause 6.8.3 of TS 26.253.
- PLC in the OMASA format decoder can be found in clause 6.9.8 of TS 26.253.
7 SID frame concealment operation p. 9
In the case of the loss of an SID frame, the comfort noise will be generated based on the last received SID frame.
8 Error concealment for IVAS split rendering p. 9
The intermediate audio format of the IVAS split rendering feature comprises coded pose correction metadata and coded binaural audio. The binaural audio may be encoded using the LCLD coding format or the LC3plus coding format. The respective PLC schemes are described in TS 26.253 as follows:
- PLC for pose correction metadata is described in clause 7.6.3.5 of TS 26.253.
- PLC for LCLD binaural audio coding is described in clause 7.6.4.4 of TS 26.253.
- PLC for LC3plus binaural audio coding is described in clause 7.6.4.6 of TS 26.253.
$ Change history p. 9
![]()
![]()